
VaultGemma: The world’s most capable differentially private LLM
Training LLMs with baked in differential privacy guarantees opens up so many use cases. You essentially ~promise that the LLM will not memorize any specific example. You can use this to train on sensitive data. Proprietary data. User data. Designing the privacy model (user/sequence) is crucial. Per the authors DP training is currently 5 years behind modern LLM training. So we can have a private GPT2. I think once we hit GPT3-level we are good to go to start using this.
Our new research, “ Scaling Laws for Differentially Private Language Models”, conducted in partnership with Google DeepMind, establishes laws that accurately model these intricacies, providing a complete picture of the compute-privacy-utility trade-offs. Guided by this research, we’re excited to introduce VaultGemma, the largest (1B-parameters), open model trained from scratch with differential privacy. We are releasing the weights on Hugging Face and Kaggle, alongside a technical report, to advance the development of the next generation of private AI.
1B param model training with differential privacy?? This looked like a far away dream 4-5 years ago. DP was constraint to small toy examples. This enables training models are highly sensitive information. So many scenarios unlocked.
To establish a DP scaling law, we conducted a comprehensive set of experiments to evaluate performance across a variety of model sizes and noise-batch ratios. The resulting empirical data, together with known deterministic relationships between other variables, allows us to answer a variety of interesting scaling-laws–style queries, such as, “For a given compute budget, privacy budget, and data budget, what is the optimal training configuration to achieve the lowest possible training loss?”
This is a hyper parameter search done once so we don’t have to all do it again and again.
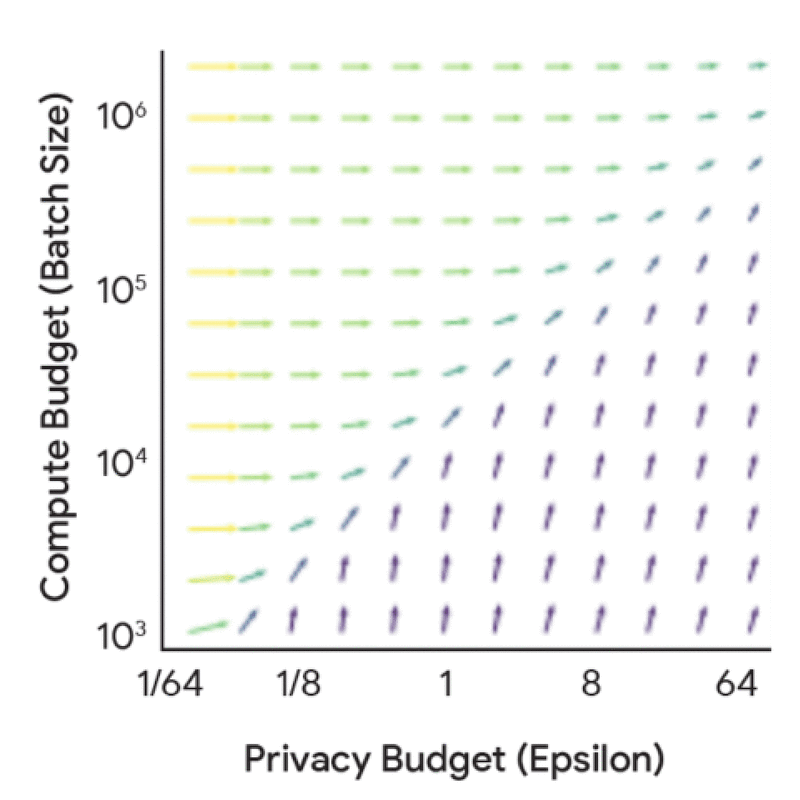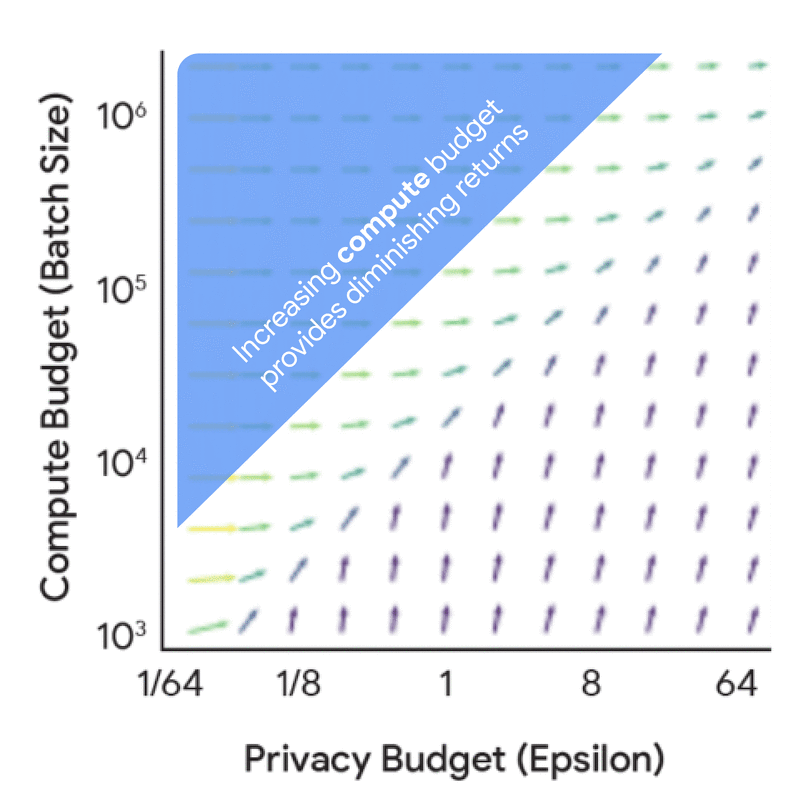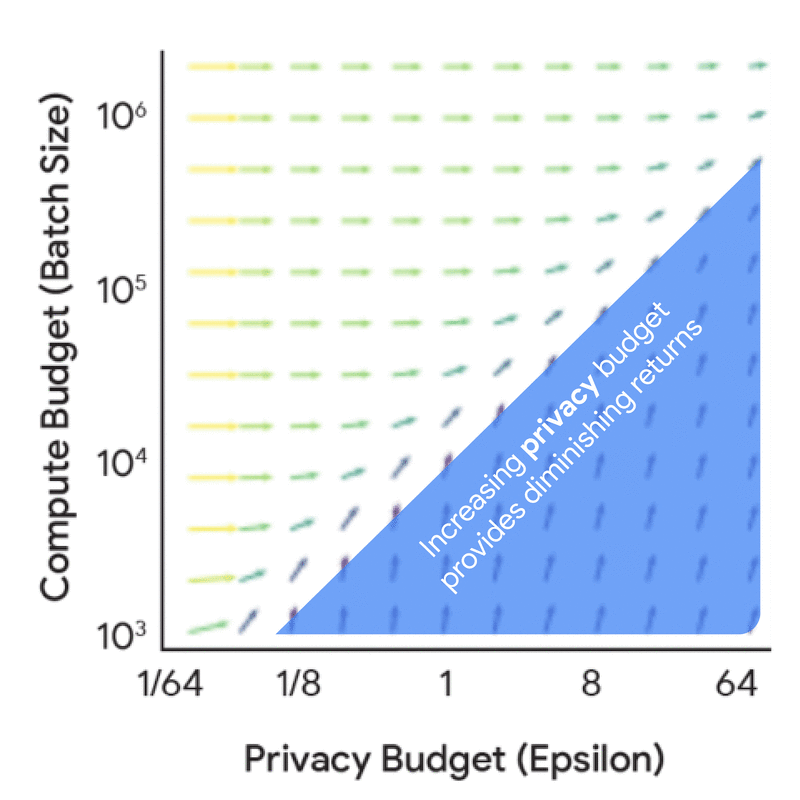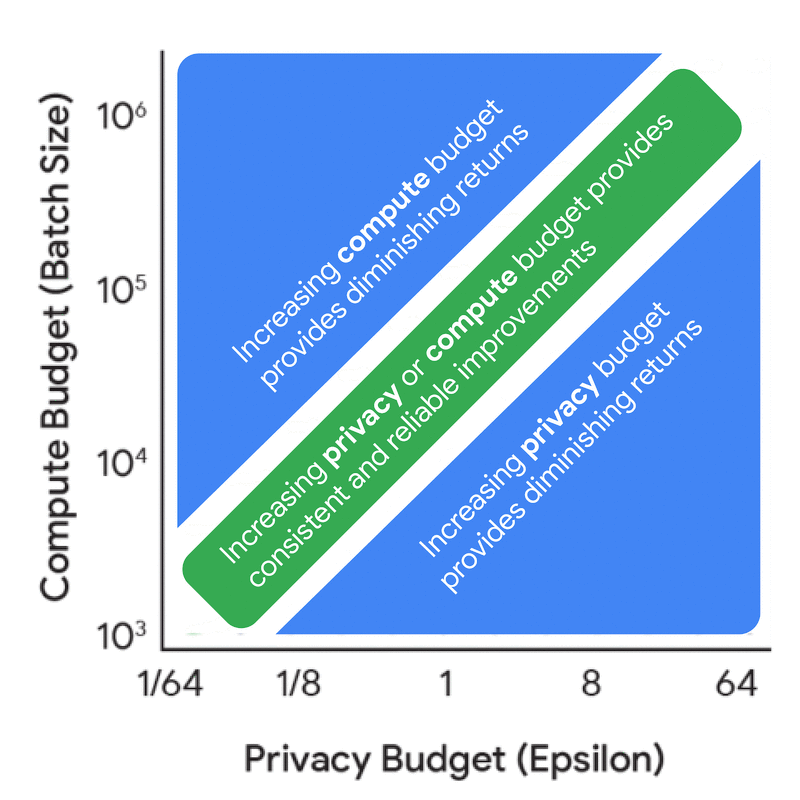
Increasing either privacy or compute budget doesn’t help. We need to increase both together.
This data provides a wealth of useful insights for practitioners. While all the insights are reported in the paper, a key finding is that one should train a much smaller model with a much larger batch size than would be used without DP. This general insight should be unsurprising to a DP expert given the importance of large batch sizes. While this general insight holds across many settings, the optimal training configurations do change with the privacy and data budgets. Understanding the exact trade-off is crucial to ensure that both the compute and privacy budgets are used judiciously in real training scenarios. The above visualizations also reveal that there is often wiggle room in the training configurations — i.e., a range of model sizes might provide very similar utility if paired with the correct number of iterations and/or batch size.
My intuition is that big batch size reduce the criticality of any individual example and reduce variance in the overall noise, which works nicely with DP smoothing noise.

“The results quantify the current resource investment required for privacy and demonstrate that modern DP training yields utility comparable to non-private models from roughly five years ago.”
Sequence-level DP provably bounds the influence of any single training sequence (example) on the final model. We prompted the model with a 50-token prefix from a training document to see if it would generate the corresponding 50-token suffix. VaultGemma 1B shows no detectable memorization of its training data and successfully demonstrates the efficacy of DP training.
So we can now train an LLM that doesn’t remember API keys or license keys if they were only seen once. Nice!



