
AI security notes 6/27 - Joshua Saxe
Subscriptions
Ctrl + K
Sign inCreate account
AllListenPaidSavedHistory
Sort byPriorityRecent

10:05 AM
The AI & Healthcare Opportunity
Part Two of How AI Can Help Improve the US Healthcare System
Eric Flaningam∙11 min read

9:38 AM
Why AI Experts Are Moving from Prompt Engineering to Context Engineering
How giving AI the right information transforms generic responses into genuinely helpful answers
Nir Diamant∙8 min read


Platforms, AI, and the Economics of BigTech
8:30 AM
How to intellectually debate AI while completely missing the point
Why both sides of the argument on AI miss the point
Sangeet Paul Choudary∙7 min read

8:30 AM
How to use AI to get out of Excel Hell
I spoke to a CFO of a $300 million company who said, Every financial metric is bullshit.
AI CFO Office∙4 min read

8:02 AM
OpenAI Released an Agent, XAI Released an e-girl
The Weekend Leverage, July 20.
Evan Armstrong∙8 min read


7:15 AM
Important Notice: Beware of Unauthorized Sales of SemiVision Reports
By SemiVision Research
SEMI VISION∙1 min read


6:57 AM
Deep Dive on Thinky’s Seed Round (Part II)
This is a Multimodal Sovereign AI startup. The first of its kind.
Michael Spencer∙24 min read


6:00 AM
The Sunday Morning Post: ‘Science Is the Belief in the Ignorance of Experts’
The people who built the technology we rely on were often crazy, wrong, or both.
Derek Thompson∙7 min read

2:00 AM
The Case For Multi-disciplinary Thinking
The best Intellectual Edge we can have.
The Intellectual Edge∙11 min read

12:08 AM
Human Grit vs. Smart Code: Psyho Wins, AI Is Right Behind
🚩 What Happened
AI & Tech Insights∙3 min read


Jul 19
16 chatgpt myths.
No, ChatGPT does not ‘read’ the entire internet.
Ruben Hassid∙6 min read


Jul 19
How Linear Built a $1.25B Unicorn with Just 2 PMs
Linear’s Head of Product Nan Yu goes deep on the Linear Method
Aakash Gupta∙ 1 hr listen

Jul 19
Jensen Huang on AI & Jobs🤖, 12 VCs Took Half the Money in H1🏦, Murati’s $12B AI Lab Has No Product Yet🧬
If you’re building, investing, or just trying to stay ahead of the curve, you’re in the right place.
Ruben Dominguez Ibar and Chris Tottman∙4 min read

Jul 19
Best AI Prompt to Humanize AI Writing
Free AI prompt you can use with any LLM to help reduce telltale signs of AI text.
Sabrina Ramonov 🍄∙3 min read

Jul 19
Seek Sunlight
Here We Are Again At The Twilight
Kyle Harrison∙4 min read


Jul 19
EP172: Top 5 common ways to improve API performance
What other ways do you use to improve API performance?
ByteByteGo∙6 min read


Jul 19
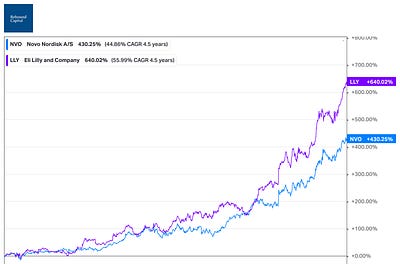
Betting on GLP-1
Buying the haystack
Market Sentiment and Rebound Capital∙10 min read

Jul 19
Will AI Really Doom Us? 3 Hard Facts That Say ‘Don’t Panic’
A data-driven, plain-English letter to friends who lie awake fearing an AI apocalypse—why today’s systems fall short of doomsday hype and where the real risks really lie
Nate∙ 14 min watch


Jul 19
The CEO’s #1 Job: Capital Allocation
Today we’re talking about capital allocation, and how it’s one of the most powerful, yet least discussed, skills a CEO needs to learn.
CJ Gustafson∙ 14 min watch


Jul 19
I read Claude’s prompt. Here are 5 tips to master prompt engineering.
The simplest way to find the right LLMs. Copying code from ChatGPT won’t make you an AI Engineer.
Paul Iusztin∙5 min read

Get app

Subscribe
AI generated code security risks stem from basic LLM limitations; we should frame prompt injection models like other detection and response tools

Jun 27, 2025

Sources of vibe coding risk
We know AI coding agents can write blatantly insecure code or cause slopsquatting risks. But a deeper and more enduring issue will be AI’s lack of access to tribal, implicit organizational cultural knowledge, often passed down by oral tradition, or in fragmented, poor documentation, required to understand what ‘secure code’ looks like in specific organizational contexts.
-
Suppose an engineering team at a hospital generates code for a patient management system with an LLM. Pre-AI, manual engineering teams with detailed, implicit knowledge of the hospital’s byzantine, legacy data tables would ensure code was HIPAA compliant. Now, the AI lacks understanding of the hospital’s counterintuitive, legacy data tables and is more liable to make mistakes.
-
Or, suppose a bank employs AI to automate changing the bank web app’s business logic. The bank’s engineering team maintains a hairball of workarounds and patches to their business logic that makes their code work correctly. Moving to AI generated code risks landing code that misunderstands the meaning of complicated, counterintuitively named sensitive data.
Another enduring source of risk: when user requests are underspecified, AI ‘fills in the blanks’ in ways that may be misaligned with the engineer’s intentions:
-
“Spin up an S3 bucket I can drop assets into from my script” … doesn’t specify any of the security attributes of this operation, hazarding the model implementing the code but in an insecure way for that specific business context.
-
“Write me a login form for my app” … doesn’t specify how credentials are to be stored and may make generically correct security decisions that are wrong in a specific programming context.
Of course, even when full context is available, AI coding systems also have poorer code security understanding than human engineering teams
-
Yes, AI can now win competitive coding competitions; buthuman teams of programmers can implement the Linux kernel, or the Unity game engine, or the software that drives a Waymo vehicle; let’s not kid ourselves, AI’s capabilities are still a pale shadow of what human teams can accomplish.
-
Given this, do we really imagine vibe coded code will have the security awareness that skilled teams of human programmers have, especially given AI’s lack of organizational knowledge or ability to learn over time?
As an aside, these are all reasons that AI won’t replace human engineers in the foreseeable future and will remain a ‘power tool’ requiring significant hand holding and human review.
Gaps in achieving superhuman performance at secure coding
Much reduces to the alignment problem in AI security, including problems in secure AI coding
-
Misalignment is inevitable when models don’t have the implicit context that human engineers have; this is a hard problem that won’t be solved for awhile
-
We should condition AI coding agents to carefully interact with human engineers as they code, asking for clarity versus assuming when it comes to critical, sensitive code blocks
-
We should also develop new programming paradigms in which human engineers specify programs precisely, and AI agents iterate until they’ve built a program that satisfies the specifications
Opportunities in vuln discovery and remediation
Lots of new and interesting work targets vulnerability discovery and remediation. Notably, most existing research targets finding and fixing generic bugs that don’t depend on specific organizational context. A couple papers I found interesting recently:
-
Generation‑time self‑patching; SGCode (NJIT + UIUC) inserts static analyzers into the generation loop so GPT‑4 corrects its own output before it ever reaches the developer, eliminating many OWASP‑top‑10 issues with negligible latency.
-
Retrieval‑augmented fixes; SOSecure (CMU) shows that fetching relevant Stack Overflow discussions after an LLM produces code raises GPT‑4’s fix‑rate on LLMSecEval from 56 % to 91 %; the community knowledge gives the model concrete examples of how others hardened similar snippets.
-
Berkeley’s new CyberGym benchmark shows how hard AI for code security in the real world will be; the best LLM+scaffolding combo reproduced 11.9 % of real‑world bugs scattered across 188 open‑source projects, struggling most with logic errors that hinge on project‑specific assumptions.
-
SecRepoBench (April 2025), a 318-task benchmark built from 27 real C/C++ repos; testing 19 leading LLMs showed they “struggle with generating correct and secure code” across 15 CWE categories.
-
Georgetown CSET issued the brief “ Cybersecurity Risks of AI-Generated Code” (Nov 2024) containing a detailed study of general weaknesses in LLM code and warning of a feedback loop where insecure AI code contaminates future training data.
Prompt‑injection guardrails: instrumentation, not silver bullets
Prompt injection detection models can be easily bypassed by AI redteamers. The headlines tend to suggest this means the these models are “broken,” but that framing misses how these tools are meant to be used.
Prompt injection models are for AI detection and response
-
Treat them as about as brittle (but just as indispensable) as all the other security signals detection and response teams use, like sigma rules, yara rules, snort rules, malware detection ML models.
-
Retrain them regularly on your current set of known jailbreaks and prompt injection attacks on the one hand, and on new benign LLM traffic on the other.
-
Only apply them after you’ve closed any severe security risks in AI applications deterministically, through the application logic itself.
-
This, of course, is how to approach security detection and response anyways; as a layering of brittle detection signals that we iteratively improve as part of an operational loop that is emergently robust.
-
I find it interesting some folks are treating prompt injection model bypasses as ‘vulnerabilities’; to me this feels a bit like calling a bypass for a detection rule base that looks for known malware families a “vulnerability”.
-
If we’re relying on detection rules, and detection models, to resist red teaming (versus treating them as partial components of a larger strategy), we need to reconsider our overall strategy.
Related work (2024 ‑ 2025)
Google’s GenAI Security Team blogged “ Mitigating Prompt Injection with a Layered Defense Strategy” detailing how they situate prompt injection defense within their larger strategy.
PI‑Bench is an interactive benchmark that mutates prompts in real time; baseline detectors drop from F1 0.82 on familiar attacks to 0.41 on unseen variants. The study quantifies how brittle today’s guardrails are when adversaries shift tactics—a direct validation of why SOC‑style iterative training is needed.
SoK: Evaluating Jailbreak Guardrails for LLMs surveyed 40 guardrail papers, proposed a six‑dimension taxonomy, and showed that mixing statistical and rule‑based defenses yields the best risk–utility trade‑off.
Subscribe to Joshua Saxe
Launched 3 months ago
Machine learning, cyber security, social science, philosophy, classical/jazz piano. Currently at Meta working at the intersection of Llama and cybersecurity
Subscribe
By subscribing, I agree to Substack’s Terms of Use, and acknowledge its Information Collection Notice and Privacy Policy.
![]()


4 Likes∙
4
2



