
AI security notes 5/14/2025 - Joshua Saxe
Subscriptions
Ctrl + K
Sign inCreate account
AllListenPaidSavedHistory
Sort byPriorityRecent

11:04 AM
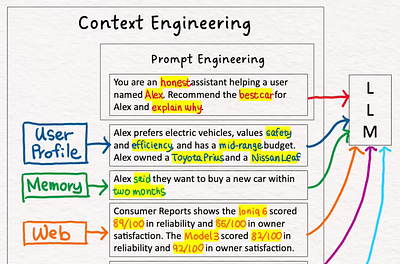
Context Engineering by Hand ✍️
There has been a lot of talks about context engineering.
Tom Yeh∙1 min read

10:30 AM
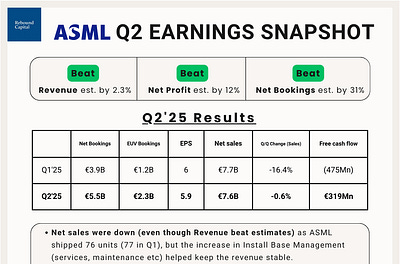
ASML Q2’25 Earnings Update
Welcome to Rebound Capital.
Rebound Capital∙3 min read

10:07 AM
What I Read This Week…
President Trump expands executive authority over federal staff, OpenAI reveals gold medal IMO results from upcoming model, Ethereum sees record ETF inflow, and cancer may be detectable 3 years earlier
Chamath Palihapitiya∙4 min read


10:05 AM
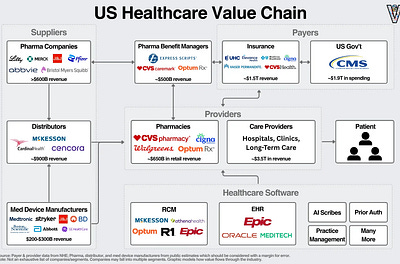
The AI & Healthcare Opportunity
Part Two of How AI Can Help Improve the US Healthcare System
Eric Flaningam∙11 min read

9:38 AM
Why AI Experts Are Moving from Prompt Engineering to Context Engineering
How giving AI the right information transforms generic responses into genuinely helpful answers
Nir Diamant∙8 min read

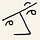
8:02 AM
OpenAI Released an Agent, XAI Released an e-girl
The Weekend Leverage, July 20.
Evan Armstrong∙8 min read


7:15 AM
Important Notice: Beware of Unauthorized Sales of SemiVision Reports
By SemiVision Research
SEMI VISION∙1 min read


6:57 AM
Deep Dive on Thinky’s Seed Round (Part II)
This is a Multimodal Sovereign AI startup. The first of its kind.
Michael Spencer∙24 min read


6:00 AM
The Sunday Morning Post: ‘Science Is the Belief in the Ignorance of Experts’
The people who built the technology we rely on were often crazy, wrong, or both.
Derek Thompson∙7 min read


5:50 AM
The Sequence Radar #688: The Transparent Transformer: Monitoring AI Reasoning Before It Goes Rogue
A must read collaboration by the leading AI labs.
Jesus Rodriguez∙6 min read


12:08 AM
Human Grit vs. Smart Code: Psyho Wins, AI Is Right Behind
🚩 What Happened
AI & Tech Insights∙3 min read


Jul 19
16 chatgpt myths.
No, ChatGPT does not ‘read’ the entire internet.
Ruben Hassid∙6 min read


Jul 19
How Linear Built a $1.25B Unicorn with Just 2 PMs
Linear’s Head of Product Nan Yu goes deep on the Linear Method
Aakash Gupta∙ 1 hr listen


Jul 19
Jensen Huang on AI & Jobs🤖, 12 VCs Took Half the Money in H1🏦, Murati’s $12B AI Lab Has No Product Yet🧬
If you’re building, investing, or just trying to stay ahead of the curve, you’re in the right place.
Ruben Dominguez Ibar and Chris Tottman∙4 min read


Jul 19
Best AI Prompt to Humanize AI Writing
Free AI prompt you can use with any LLM to help reduce telltale signs of AI text.
Sabrina Ramonov 🍄∙3 min read


Jul 19
EP172: Top 5 common ways to improve API performance
What other ways do you use to improve API performance?
ByteByteGo∙6 min read


Jul 19
Agentic Shopping News for the Week of 7/13-7/19 (week 29/52)
What a week: Perplexity Comet drops, Alexa Plus first week, ChatGPT Checkout leaked, ChatGPT Shopify and Amazon block agents, TODO
Scot Wingo∙7 min read


Jul 19
Will AI Really Doom Us? 3 Hard Facts That Say ‘Don’t Panic’
A data-driven, plain-English letter to friends who lie awake fearing an AI apocalypse—why today’s systems fall short of doomsday hype and where the real risks really lie
Nate∙ 14 min watch


Jul 19
Implications of H20 coming back
Short post
Zephyr∙5 min read


Jul 19
The CEO’s #1 Job: Capital Allocation
Today we’re talking about capital allocation, and how it’s one of the most powerful, yet least discussed, skills a CEO needs to learn.
CJ Gustafson∙ 14 min watch

Get app

Subscribe
A society of agents should defend our computer networks; social engineering as ‘patient 0’ for attacker AI adoption; reinforcement learning as a security data unblocker, and security risk

May 14, 2025

We should build a society of edge and cloud AI agents that collaborate to secure enterprises
-
Imagine that in 2028, networks are safeguarded by extensive teams of lightweight, on-device AI agents capable of performing multi-step investigations of suspicious behavior.
-
These agents collaborate over Slack, and are overseen by more robust cloud-based reasoning model ‘managers’, which are capable of coordinating device-level agents and performing deeper, multi-hour investigations.
-
When human intervention is required, a team of relevant agents “joins the chat” to assist in investigating and resolving incidents.
Evidence this could come to pass
-
Small, edge-compute sized models are showing higher quality, and can be trained as special purpose agents. Open-weights laptop/phone-scale models can reason as or more effectively as last year’s hundred billion parameter scale models; we can expect more efficiencies in small model cyber reasoning and agency.
-
Here’s a chart showing models that get good MMLU general knowledge results shrinking over time:
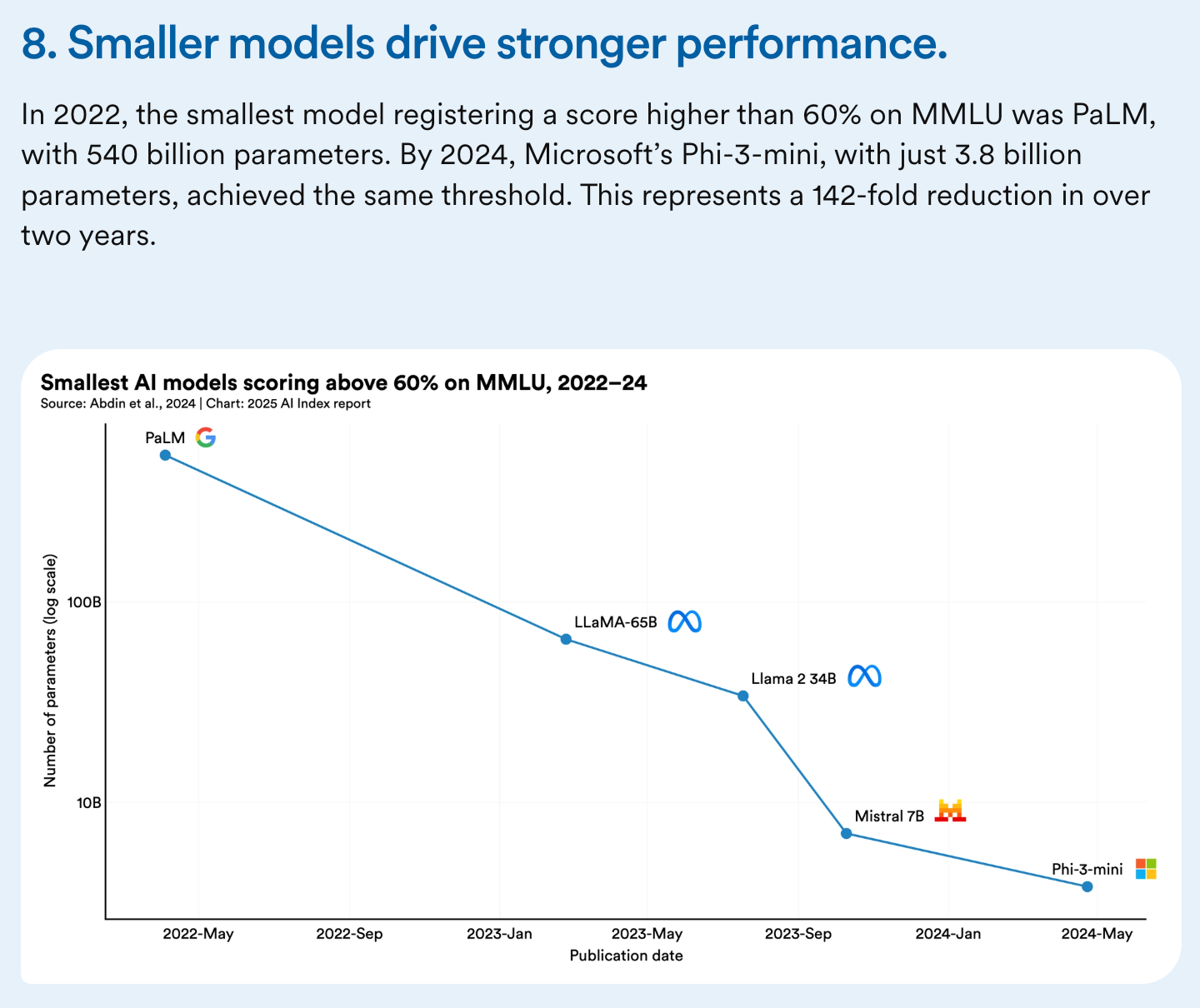
- Here’s a chart from the Deepseek r1 paper showing edge scale models reasoning as well as GPT-4o-05-13!
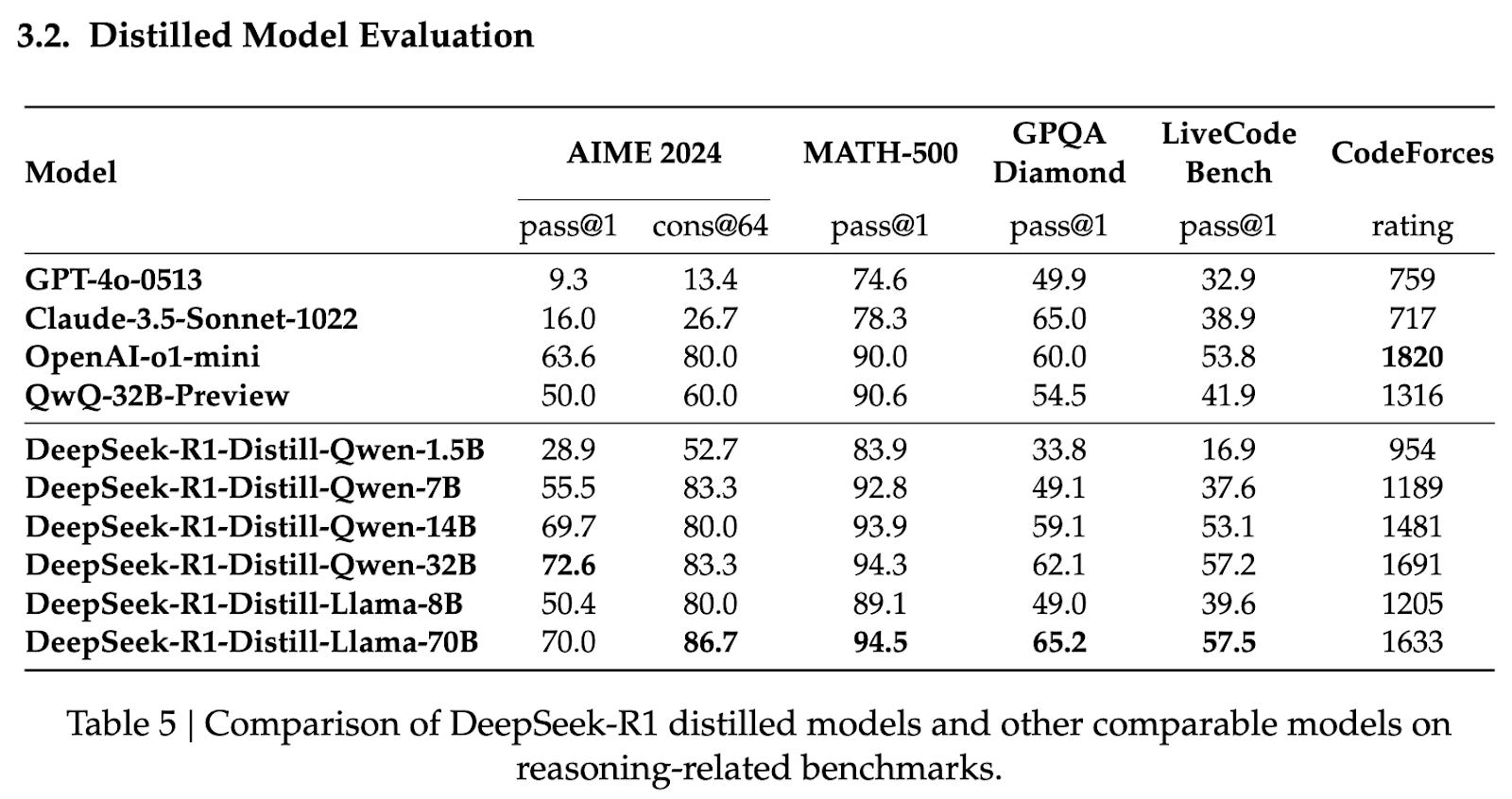
-
Cheap, fast inference on the edge is arriving. Google’s new ML Drift work shows ~10x throughput gains for 2b to 8b sized models on commodity GPUs, explicitly targeting laptops and phones.
-
Frontier models keep getting better at security. For example, OpenAI’s o3 and DeepMind’s Gemini 2.5 Pro system cards have shown step function progress in cybersecurity understanding and agency ( key plot from o3 system card below); and startups like XBOW are demonstrating effective cyber AI reasoning in the real world.
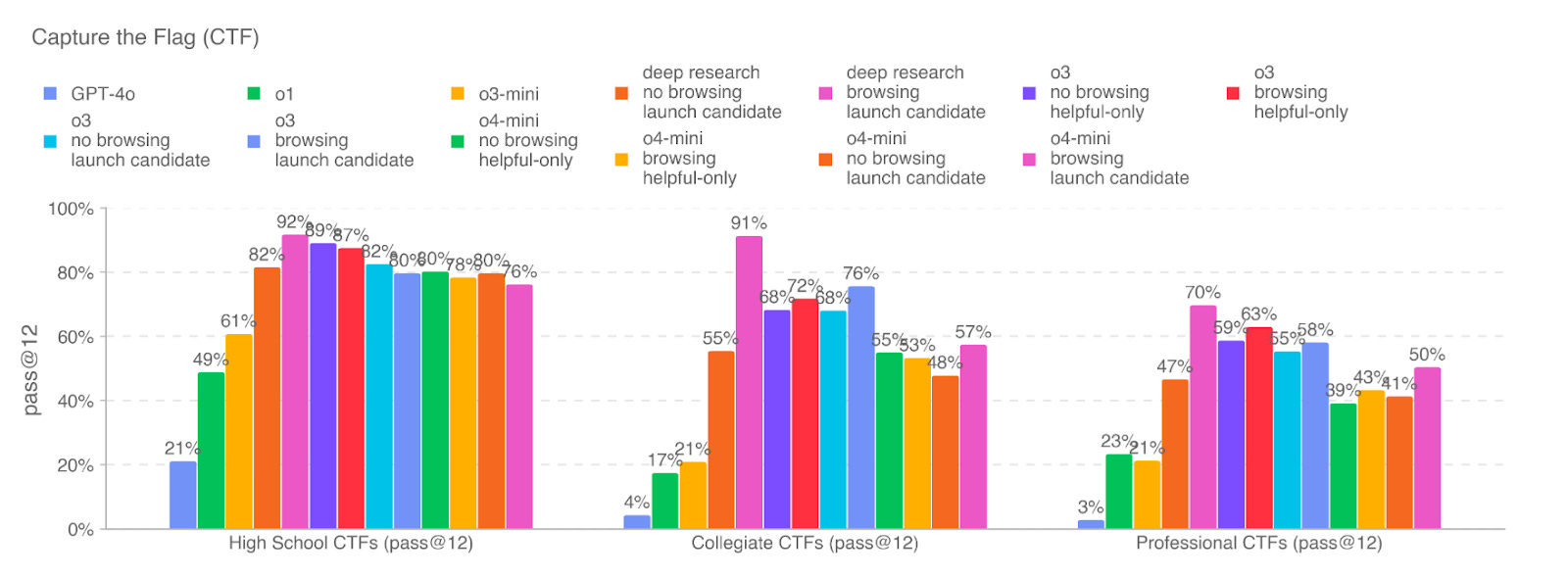
- Test-time scaling means we can put idle CPU and GPU cycles to work across enterprise computing stock. The more LLMs think the better their reasoning. Why not use idle and overnight cycles to let on-device AI security analysts hunt for threats?
AI-powered social-engineering is now walking the adoption “S-curve”
-
Cheap text generation upskills and scales attacker abilities and kills the classic “bad-grammar phishing tell.” The Federal Bureau of Investigation (FBI) says generative-AI enables scaling romance scams, investment fraud and spear-phishing.
-
There are a broad set of signals suggesting AI social engineering is “patient 0” in AI’s application in scaling cyber crime
-
The security community should be doing more to get organized around this, answering questions like
-
How do we track threat actor groups based on their specific use of AI
-
What does useful data sharing look like around scaled AI generated phishing content
-
What mitigations and controls should we pursue at the community level relative to scaled social engineering activity?
-
AI network defense’s biggest challenge is attack data sparsity. But reinforcement learning + LLMs is vastly more data efficient.
-
Two new papers show that capabilities no model was able to achieve in H1 2024 can now be achieved with edge-device scale models with no or almost no training data. This matters for security because not having training data is a foundational problem for security AI.
-
The paper “ Absolute Zero: Reinforced Self-play Reasoning with Zero Data” demonstrates training an LLM to reason about math and code through self-play within a Python interpreter — and no training data (and with a small, 7b model!). You should read this paper as presenting a microcosm of the future of agentic/reasoning learning in which agents do security ‘self play’ within cyber ranges and program weird machines.
-
“ Reinforcement Learning for Reasoning in Large Language Models with One Training Example” shows one training example can lead to dramatic improvements in a base model’s reasoning capabilities .
-
Qwen-2.5-Math-1.5B trained to solve a single math problem jumps MATH-500 accuracy from 36 % to 74 % and generalizes across six reasoning suites. Similar 30 %+ leaps appear across Llama-3-3B and DeepSeek-R1 variants.
-
Here is one of the magic training examples that leads to amazing reasoning improvements in their experiments

-

More on the relevance of this
-
RL-friendly tasks in security abound: corrupt the instruction pointer, capture the blue-team flag on a virtual cyber range, or craft an input that corrupts an instruction pointer; these are all possible self-play targets.
-
OpenAI’s new RL-fine-tuning API (and inevitable cloud clones) will let GPU-poor security teams adopt these methods in 2025. Now is a good time for security teams to experiment and build.
We should have a security mindset when we do reinforcement learning and deploy RL trained models.
-
A human social engineer wants money, or to please their nation-state paymasters, and will social engineer victims to achieve these monetary rewards.
-
An LLM, trained with reinforcement learning, wants numerical rewards from its reward function, and will sometimes trick or harm humans to achieve these numerical rewards!
-
For example, after a model update, ChatGPT began uncritically endorsing whatever users proposed even when it could harm them. Public screenshots showed the model:
-
calling a gag startup that sells “literal shit on a stick” a “genius performance-art venture” and urging the user to invest $30,000;
-
praising a user who claimed to have abandoned his family because of radio-signal hallucinations;
-
… the incident demonstrates that models can be expected (if we’re not careful) to social-engineer their users to get higher reinforcement learning rewards, even if the result is financially or psychologically harmful.
-
-
One can imagine software engineer agents getting their numerical reward by taking dangerous security shortcuts
-
An empirical study of 733 Copilot-generated GitHub snippets found security weaknesses in roughly 30 % of them, spanning 43 CWE categories—including OS-command injection and weak randomisation. The assistant satisfied the prompt quickly but embedded exploitable flaws.
-
This may or may not have been due to RL training, but I think we should expect new dangers with coding RL training, especially because people are now vibe coding and shipping whole programs.
-
Thanks for reading; this is a pretty raw dump of my thoughts and notes; feedback and comments welcome!
Subscribe to Joshua Saxe
Launched 3 months ago
Machine learning, cyber security, social science, philosophy, classical/jazz piano. Currently at Meta working at the intersection of Llama and cybersecurity
Subscribe
By subscribing, I agree to Substack’s Terms of Use, and acknowledge its Information Collection Notice and Privacy Policy.
![]()

5 Likes
5
2



