
AI Agents Fail in Novel Ways, Put Businesses at Risk
![]()
News, news analysis, and commentary on the latest trends in cybersecurity technology.
AI Agents Fail in Novel Ways, Put Businesses at Risk
Microsoft researchers identify 10 new potential pitfalls for companies that are developing or deploying agentic AI systems, with failures potentially leading to the AI becoming a malicious insider.

Robert Lemos, Contributing Writer
May 7, 2025
5 Min Read

Source: Microsoft
LinkedinFacebookTwitterRedditEmail
Companies rushing to deploy poorly understood AI agents with the capability to take actions inside their corporate environment may wonder what could go wrong.
Turns out quite a bit.
At least 10 new broad classes of failures exist for agents powered by artificial intelligence (AI) and deployed by companies — failures that could compromise the safety or security of the AI application or environment, stated Microsoft’s AI Red Team in a paper released on April 24. While the failures of large language models (LLMs) may result in the release of sensitive or dangerous information or abusive language, the failure modes identified by Microsoft could lead to agents acting on behalf of the attacker, making bad decisions, or causing harm to the user.
These novel failure modes include the compromise of agents, the injecting into a system of rogue agents, or the impersonation of legitimate AI workloads by attacker-controlled agents, according to Microsoft’s “Taxonomy of Failure Mode in Agentic AI Systems” paper. Companies need to focus on a holistic approach to security, but some risks are more likely, says Pete Bryan, principal AI security research lead for Microsoft’s AI Red Team.
“Based on [our] research and experience [with] agentic systems being developed today, there are several issues in the taxonomy that we flag as being more immediate challenges,” he says. “These include agent compromise, indirect prompt injection, human-in-the-loop bypass, and memory poisoning.”
Related: NIST to Implement ‘Deferred’ Status to Dated Vulnerabilities
The focus on classifying the risks posed by AI agents into broad groups comes as technologists and AI firms strike a near-hyperbolic tone about an agentic future. AI agents hold the promise of handling complex tasks in existing platforms using only natural language for direction, essentially becoming “virtual co-workers” in the enterprise and helping supercharge productivity, stated management consulting firm McKinsey in a July 2024 report about Gen AI-enabled agents.
”[I]t is not too soon for business leaders to learn more about agents and consider whether some of their core processes or business imperatives can be accelerated with agentic systems and capabilities,” the McKinsey analysis stated. “This understanding can inform future road-map planning or scenarios and help leaders stay at the edge of innovation readiness.”
Many AI Approaches, Diverse Defenses
Yet the diversity of AI technologies — with a variety of architecture, capabilities, and objectives — means that enumerating the risks posed by an AI agentic system remains complex. Knowing which failure modes are the most important for a company to remediate is specific to the AI agents they use, Microsoft’s Bryan says.
Related: Deepwatch Acquires Dassana to Boost Cyber-Resilience With AI
In general, agent compromise, indirect prompt injection, human-in-the-loop bypass, and memory poisoning are the top threats, as cited by Bryan. These attacks could allow an attacker to co-opt an agent, cause harm to users, or erode trust in the system.
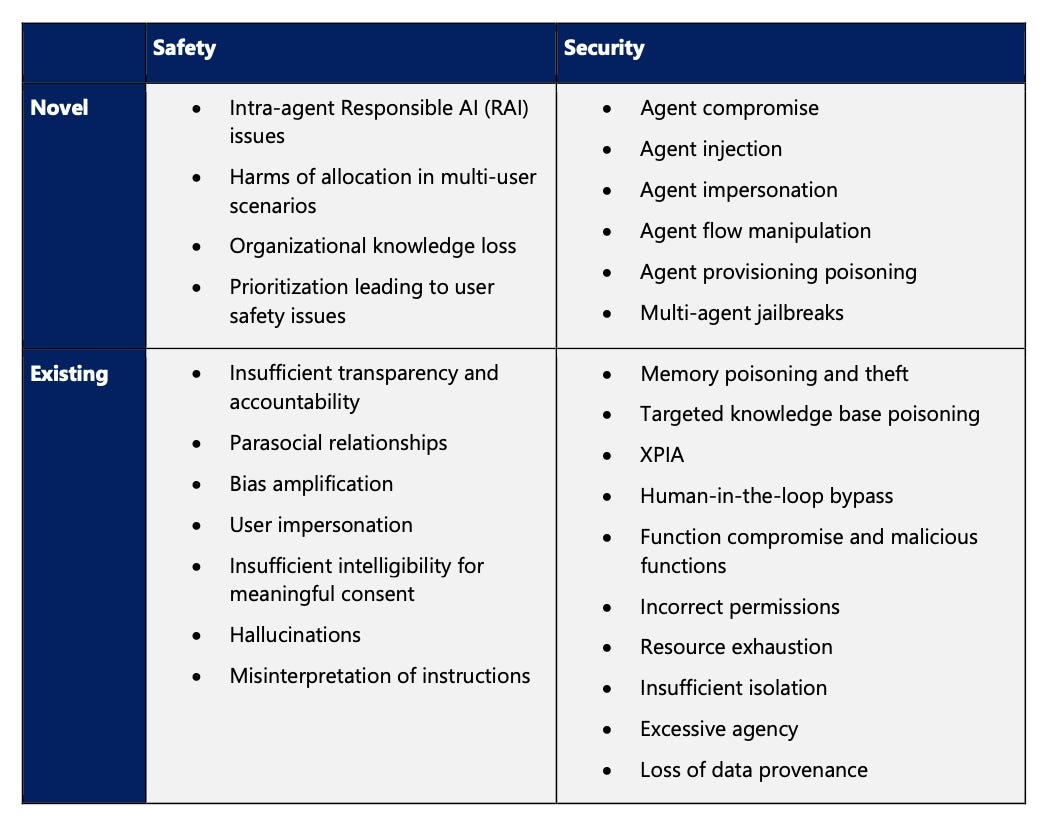
Microsoft added 10 different novel ways that AI agents could fail, harming security and safety. Source: Microsoft
In a case study of memory poisoning, for example, the Microsoft researchers showed that an AI agent that parses email and takes actions based on the content can be easily co-opted — if not hardened against such an attack — by an attacker who embeds a command in an email. Sending an email with a command that modifies that agent’s knowledge base, or memory, leads to unwanted actions, such as forwarding messages with specific topics to an attacker.
Companies need to model the threats to each AI agent, Bryan says.
“Development teams should leverage practices such as threat modeling to help identify and prioritize the issues specific to the systems they are building,” he says. And techniques like memory poisoning “can significantly increase overall attack success rates, provide a persistent and difficult-to-detect attack vector for threat actors, and are relatively simple to conduct.”
Related: Google Launches Open Source Patch Validation Tool
Defense-in-Depth for AI
While some companies are worried about the risks posed by AI, security and safety are often not the top concern. In its report, for example, McKinsey made scant mention of the risks of AI agents but did note that about 41% of companies are working to mitigate cybersecurity risk in its “State of AI” report for 2025.
Because of the risks posed by AI agents, Microsoft recommends that companies do extensive design reviews, monitor and log agent activity during production, and conduct frequent red-team testing. The best approach distills down to common cybersecurity advice: pursue defense-in-depth, says Microsoft’s Bryan.
“The most effective place to tackle [these issues] is at the architectural level and earlier in the design process so that developers can start to incorporate them better,” he says. “As a foundation, companies should be carefully identifying and implementing trust boundaries between the various components of agentic AI systems, as well as ensuring that, just as with user data, they are not treating the output of generative AI as fully trusted.”
Overall, Microsoft recommends that companies heavily monitor AI agents. Tools — such as the Python Risk Identification Tool for GenAI (PyRIT) — can help, but understanding what AI agents are doing and looking out for anomalous behavior will help catch failure modes, Bryan says.
“To build confidence in a system’s safety and security, companies will need to combine effective threat modeling with automated assessments and manual red teaming prelaunch,” he says. “But this also needs to be supported by logging and monitoring in production, as well as continuous automated testing over the lifetime of the system.”
Microsoft released its own AI red-teaming agent for generative AI systems in early April as a public preview.
LinkedinFacebookTwitterRedditEmail
About the Author

Robert Lemos, Contributing Writer
Veteran technology journalist of more than 20 years. Former research engineer. Written for more than two dozen publications, including CNET News.com, Dark Reading, MIT’s Technology Review, Popular Science, and Wired News. Five awards for journalism, including Best Deadline Journalism (Online) in 2003 for coverage of the Blaster worm. Crunches numbers on various trends using Python and R. Recent reports include analyses of the shortage in cybersecurity workers and annual vulnerability trends.
See more from Robert Lemos, Contributing Writer
Keep up with the latest cybersecurity threats, newly discovered vulnerabilities, data breach information, and emerging trends. Delivered daily or weekly right to your email inbox.
More Insights
Webinars
- Securing the Software Supply Chain: Managing Third Party Risks May 14, 2025
- Cybersecurity Strategies for Small and Medium-Sized Businesses May 15, 2025
Events
You May Also Like
Latest Articles in DR Technology
3 Min Read
- Getting Outlook.com Ready for Bulk Email Compliance May 1, 2025 |
3 Min Read
4 Min Read
- Cisco Boosts XDR Platform, Splunk With Agentic AI Apr 30, 2025 |
4 Min Read



