
Open Problems in Mechanistic Interpretability

Mathy AI Substack
SubscribeSign in
Open Problems in Mechanistic Interpretability
Mike’s Daily Paper Review – 25.06.25

Jun 26, 2025
2
Share
Mechanistic interpretability is perhaps the most ambitious field today for understanding how artificial intelligence truly works. This is not about hand-wavy explanations or colorful saliency maps, but about reverse engineering the networks themselves, namely, gaining a real understanding of how a neural network solves a problem: which internal components are activated, in what sequence, under what logic, and how exactly they give rise to generalization.
Thanks for reading Mathy AI Substack! Subscribe for free to receive new posts and support my work.
Subscribe
The core approach outlined in the paper is based on three steps: decomposing the network into small components (whether neurons, subspaces, or circuits), describing the functional role of each one, and validating those descriptions—namely, testing whether the explanation predicts behavior, and if so, to what extent. Each of these steps turns out to be far more difficult than it seems.
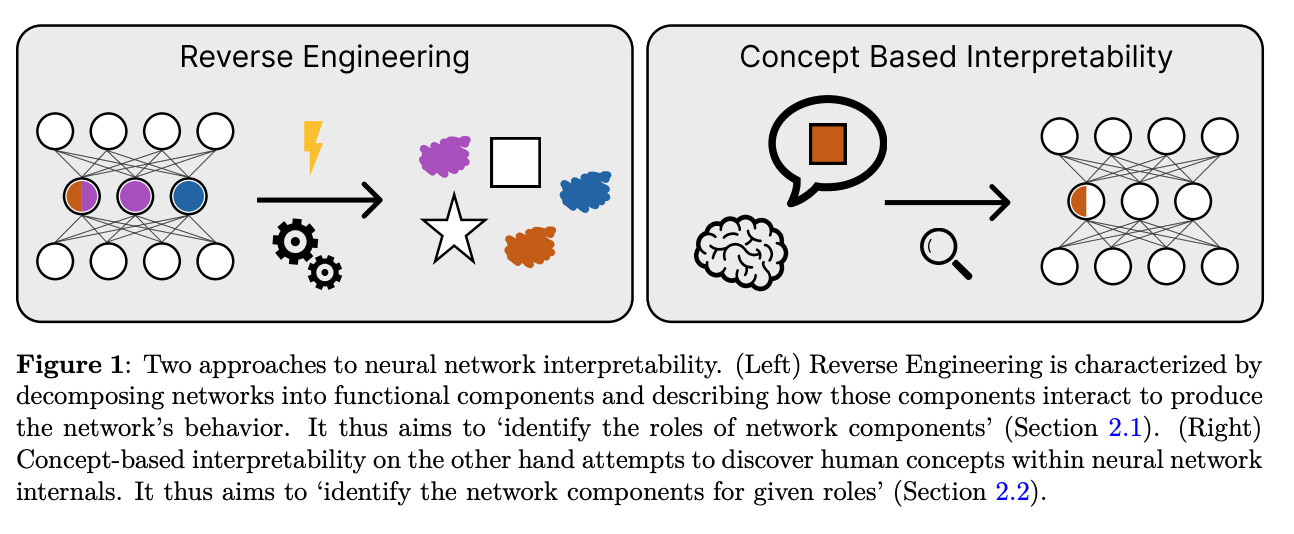
The fundamental problem is that decomposition based on network architecture: layers, neurons, attention heads, simply doesn’t work. These parts don’t align with the actual computational units of the network. Neurons are polysemantic, functional roles are spread across layers, and features are not localized to a single direction but encoded as superpositions of many vectors. Classical methods like PCA and SVD fail not due to poor implementation but because they rely on theoretical assumptions that don’t hold.
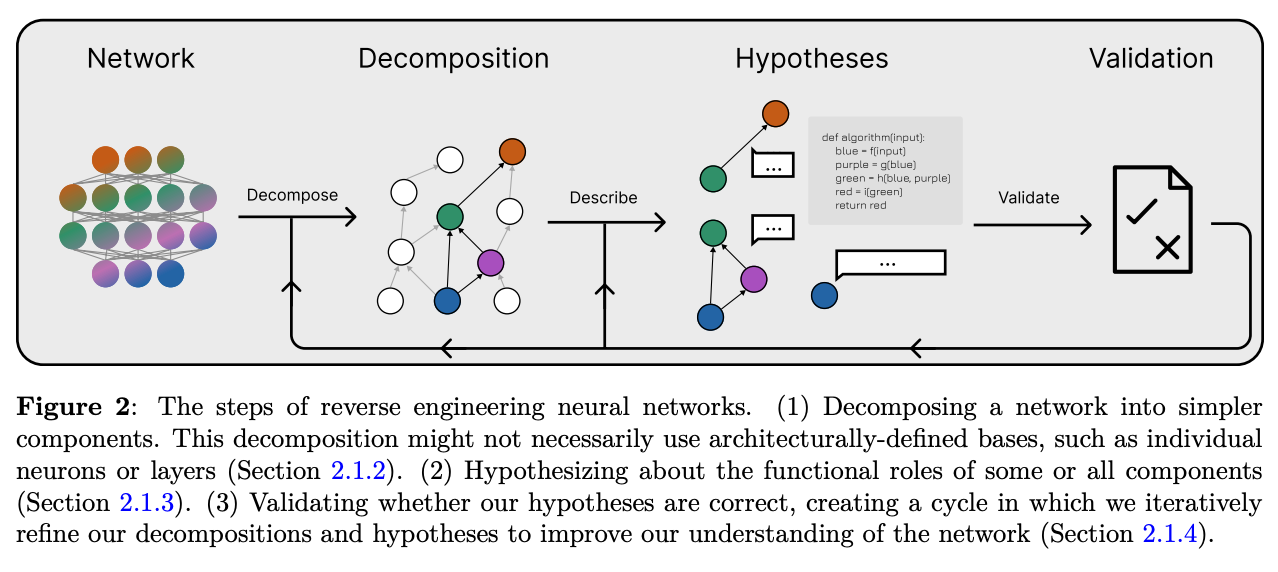
The main tool currently used is sparse dictionary learning, particularly sparse autoencoders. The idea is to train a small network that “decodes” the activations of the large model using a sparse basis of “features,” which are the latents. In practice, these methods do uncover interesting directions, but they do not explain how the computation is performed. The latents offer a static snapshot of “what was activated,” not a dynamic description of the algorithm being implemented.
There are also deep flaws: the reconstruction error between real activations and the latent approximation is large. The geometric information between features gets lost. The assumption of linearity is far from valid. And worst of all, there’s no formal theory that defines what a “feature” even is, how it arises, or what makes it a fundamental unit of understanding.
This leads to an innovative direction: perhaps we should not be interpreting models post hoc, but instead designing models that are interpretable by construction. That means models with discrete activations, enforced modularity, sparse activation functions like Top-k or SoLU, or architectures like Mixture-of-Experts that break down the computation into clearly defined submodules. The goal is to build networks that are “pre-carved” where interpretability is not a retrofit, but a built-in design principle.
Even describing the function of a single component is a tough task. For example, finding examples that strongly activate a component can be misleading. Gradient-based attribution methods are both theoretically and practically problematic. Feature synthesis, optimizing an input to activate a unit, often produces uninterpretable images. The most promising approaches rely on causal interventions: manipulating internal values and measuring their effects on the output. This includes techniques like steering (injecting specific directions into activation space) and using logit lens methods to trace direct effects on network output.
The big problem is that many explanations sound convincing but don’t hold up under pressure. They fail to predict counterfactuals, they don’t tell us what would happen if something inside the model changed. They don’t help us diagnose model failures or enable practical control. That’s why the authors propose a range of validation strategies: can the explanation predict behavior after ablation? Can we build a small model where we can test if the explanation holds? Do the latents, namely internal representations like features or computational units, help with safety tasks like detecting harmful content? Can we use explanations to actually steer the model’s behavior?
The paper also proposes building “model organisms” which are small standardized networks with open structure, which can be trained repeatedly and used to benchmark interpretability methods. Just like biology advanced through the study of fruit flies, this field needs a fixed point of reference. Such infrastructure is sorely lacking today.
The final section of the paper clarifies that mechanistic interpretability is not just a technical issue. It connects to policy, monitoring, safety, and philosophical questions: what counts as a good explanation? How can we relate microscopic structures to global function? What general principles can we extract from networks that have learned to solve problems better than humans?
In conclusion, this is a paper unafraid to tell the truth: we do not yet have a sufficient theory for decomposing networks. The linear assumptions are brittle. Features don’t live alone but live in emergent macro-structures. Interpretation must tie structure to function. And the path forward might not lie in decoding but in designing networks differently from the outset.
https://arxiv.org/abs/2501.16496
Subscribe to Mathy AI Substack
By Mike Erlihson · Launched 7 months ago
Deep learning paper reviews, blogs about machine learning techniques, LLM discussions
Subscribe
By subscribing, I agree to Substack’s Terms of Use, and acknowledge its Information Collection Notice and Privacy Policy.
2
Share
PreviousNext
Discussion about this post
CommentsRestacks
![]()
TopLatestDiscussions
What Agentic Software Really Means: Beyond LLM Wrappers and Hype
Apr 18• Mike Erlihson, Mathy AI
16

A Deep Mathematical Tour of Generative Models in Deep Learning
A short survey of the most popular generative models in deep learning
Apr 5• Mike Erlihson, Mathy AI
9
DeepSeek: Are we at the brink of a reasoning training revolution for LLMs?
A short summary of an excellent Nathan Lambert’s post: https://substack.com/@natolambert/p-155269286
Jan 24• Mike Erlihson, Mathy AI
5
See all
Ready for more?
Subscribe



